Nu är det dags för publicering av ännu ett gammalt utkast, som delvis handlar om den videoföreläsning av Tatev Abrahamyan som jag nämnde i en tidigare bloggpost.
Som jag sa då var det sedermera avstängda kommentarsfältet fullt av sexistiskt trams om hur omöjligt det är att fokusera på schack när man ser henne. För den som vill se vad jag pratar om är det bara att googla till exempel Irina Krush, en annan världsstjärna.
Någon gång runt 2015 satt i alla fall jag och de andra gubbarna på restaurangen tillika schackklubben Solrosen och surrade med någon efteranalys på brädet, som så många gånger annars. Jag tyckte mig se en fantastisk kombination, men det var inte bara det att partiet faktiskt hade tagit helt andra vändningar, utan jag kunde inte ens hitta en variant där kombinationen både hade fungerat och varit nödvändig.
Men jag gick hem och kokade ihop en ställning där min idé hade kunnat avgöra. Utan dator hade jag inte fått till det, men numera kan man ju sitta med en gratis app och flytta omkring pjäserna medan datorn analyserar.

Jag gissar att den här kombinationsövningen är ganska svår för de flesta, men det finns ju de som har skarpare schackblick än jag. Jag hade inte löst den på tusen år om jag inte hade kokat ihop den själv. Vit drar och vinner.
Den som vill får gärna försöka lösa den själv och berätta hur det gick, men pausa i så fall här, för nu kommer lösningen enligt mig och appen Smallfish. Därefter mer om Abrahamyans videoföreläsning.
Svart har fyra bönder för pjäsen, så backar man med löparen har svart inga problem. Och 1. gxh6 fallerar på grund av 1. - Qh4+. Men vit kan avlänka svarts dam med 1. Ra7!!
På 1. - Qxa7 följer 2. gxh6 g6 3. Rxg6+ Kh8 4. Rg7 (hotar 5 Rh7+!) Rg8 5. Qg5 Qa2+ 6. Kg1! och vit kommer undan schackarna. Till exempel 6. - Qa1+ 7. Bf1 Qa3 8. Kh1! Vits plan är nu att slå på g8 medan damen står på g5 för att hindra svart att slå tillbaka med kungen. Därefter kommer damschack på f6 och manövern Bf1-h3-f5. Men då måste vits kung undan från g-linjen och det måste ske i drag 8. Direkt 8. Qf6 går inte pga 8. - Qf8!
Efter 8. Kh1 följer t ex 8. - Qf8 9. Rxg8+ Qxg8 10. Qf6+ Kh7 11. Bh3 och löparen kommer till f5. Eller 8. - Qa1 9. Qf6.
Men "huvudvarianten" är att svart inte slår på a7 i drag 1 utan spelar 1. - Qd6. Då följer 2. g6! Nu kan svart inte gärna tillåta 3. Bxf7 då kungen hamnar illa och vit ger sig på h6. Här verkar det inte vara "kritiskt" utan vit har flera möjligheter. Men det finns några roliga varianter, till exempel 2. - Kh8 3. Bxf7 Qf6 4. Qc1 d3 5. Qd2 Qf4 6. Qxf4 exf4 7. Rh3 Rd6 8. e5 d2 9. exd6 d1=Q 10. Rxh6+! gxh6 11. g7+ Kh7! 12. g8=Q+! Rxg8 13. Bh5+ osv.
Så svart får istället slå löparen: 2. - bxc4 3. gxf7+ Kh8.
Nu kunde man tro att nästa drag är 4. Rg6 för att få bort svarts dam. Men då följer 4. - Qb4! varefter damen kommer runt och kan hålla fältet g5 från d2, till exempel 5. Rxg7 Qd2+ 6. Kh1 h5!! varefter vit knappast kan hoppas på något bättre än remi, till exempel 7. Rg5 Qe2 8. Rg2 Qxe4 9. Qf1 Qh4+ 10. Rh2 Qe4+ osv.
Vad som är så märkvärdigt med svarts bondedrag till h5 kommer att framgå av den rätta lösningen, som är att vit istället slår på g7 direkt utan att stanna till på g6: 4. Rxg7! Nu är det naturliga försvarsdraget 4. - Qf6 och man kan tro att vits angrepp ebbar ut. Men det finns en spektakulär forcerad matt:
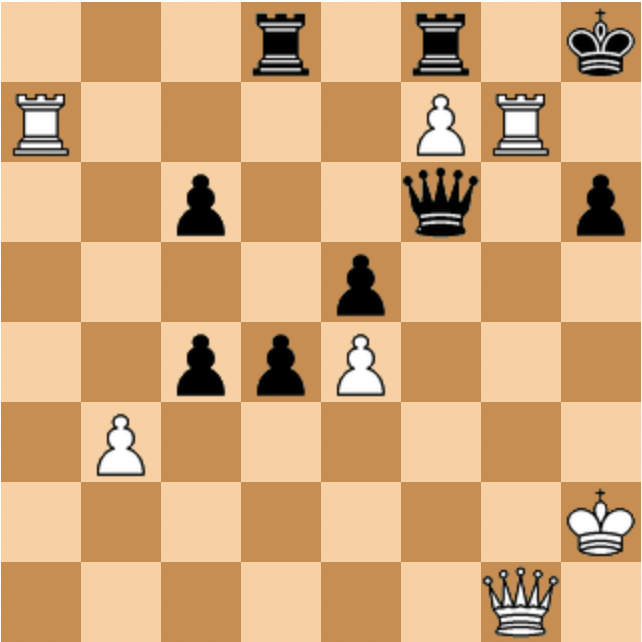
5. Rh7+! Kxh7 6. Qg8+! Rxg8 7. f8=N+! Kh8 8. Rh7#.
Om svart hade hunnit flytta bonden till h5 hade denna mattkombination inte fungerat då kungen hade kunnat smita till h6 och g5.
Så var det med det, en trevlig kväll på Solrosen med en kombination att visa gubbarna nästa gång.
Några veckor senare tittade jag på ovannämnda föreläsning från Scholastic Center of Chess, Saint Louis, Endgame Gold over Goletiani, där Tatev Abrahamyan går igenom sitt vinstparti mot Rusudan Goletiani från damernas USA-mästerskap 2015. Hela partiet finns här.
Ungefär 17.30 in i videon visar Abrahamyan en variant där hon skulle ha haft en forcerad vinst (och som Goletiani därför inte gick in i). Hon säger "There's a forced win in this position already, actually a very cool win".

En av åhörarna föreslår en lite onödigt krånglig variant som visar sig fungera, och sedan sägs inte mer om det. Men den avslutning som jag gissar att Abrahamyan hade tänkt visa, och som jag såg direkt eftersom jag kände igen den från min studie, är 44. g7+ Kh7 45. g8=Q+! Rxg8 46. f8=N+! och 47. Rh7#.
Jag scrollade ner för att se om någon hade nämnt detta i kommentarerna. Det var det inte. Däremot fanns den ena kommentaren efter den andra om "Hur ska man kunna koncentrera sig på schack när man ser henne?", "Det enda jag ser är två tunga pjäser som hänger, höhö". Och så vidare. Handlade det inte om hennes utseende så var det att hon inte är stormästare. Märkligt, för när Ben Finegold eller Yasser Seirawan pratar är det ingen som kommenterar någons utseende, och ingen klagar på att Jonathan Schrantz inte är stormästare.
Och när jag gick tillbaka till samma sida lite senare, var hela kommentarsfunktionen avstängd.
Gubbar, kan vi inte bara säga att de kvinnliga föreläsarna är charmiga och roliga, precis som vi säger om de manliga, och hålla våra eventuella sexuella fantasier för oss själva?
Och framför allt, kan vi inte bara säga att det var en snygg springarförvandling?

